《表3 特征(b)和(d)的词频矩阵》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
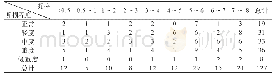
对提取的特征进行处理,将其转换成词频(Term Frequency,TF)矩阵,以便能够便捷高效地对数据进行计算。词频是指文件中的某个词在文件中出现的频率,而TF矩阵是将相互对比的两段代码中存在的关键字都放入到一个矩阵M中,然后分别计算这两段代码中各个词出现的次数。例如表2中的(b):\""select from where not exists(select from where)\""和(d):\""SELECT\\nFROM\\nWHERE NOT EXISTS(\\nSELECT\\nFROM\\nWHERE)\""。本检测算法设定保留字因大小写的不同、是否包含换行符缩进符等内容而认定为不同的关键字,于是生成的关键字矩阵M为:['(',')','SELECT','select','\\nSELECT','not','NOT','where','\\nWHERE','from','\\nFROM','exists','EXISTS'],由此便能生成出代码(b)和代码(d)的词频矩阵,如表3所示。
| 图表编号 | XD00110615100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.01 |
| 作者 | 葛文馨、魏永山 |
| 绘制单位 | 山东科技大学计算机科学与工程学院、山东科技大学计算机科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}