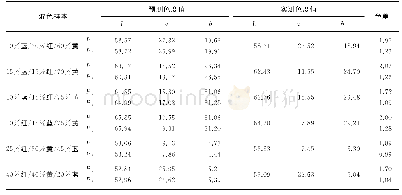
《表2 六种模型对中国上市公司测试样本的预测误判结果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:括号外数字为误判个数与所对应样本总数,括号内为误判率。这里以0.5作为区分好与差公司的判定临界值。
一般来讲,模型的检验是用对训练样本和测试样本中分类的判定准确度来表示,尤其是对训练样本外的测试样本中的判定准确度更能反映模型的泛化性和预测性。故本研究采用I类错误率、II类错误率和总误判率三个指标作为衡量模型预测准确度的标准。这里第一类错误指的是将高信用风险(信用差)公司误判为低信用风险(信用好)公司,即将ST公司判为非ST公司;第二类错误指的是将低信用风险(信用好)公司误判为高信用风险(信用好)公司,即将非ST公司判为ST公司;总误判率指所有被错判的公司数与样本公司总数的比值。此外,为对比分析,本研究还利用前面文献所提到的一些经典方法,包括BPNN、Logistic回归、SVM、DT(采用C5.0算法)及LDA等构建了相应的信用评估模型,表2为所构建的六种模型对中国上市公司测试样本集的预测结果。
| 图表编号 | XD00108515100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.20 |
| 作者 | 熊志斌、吴维烨 |
| 绘制单位 | 华南师范大学数学科学学院、华南师范大学金融工程与风险管理研究所、华南师范大学数学科学学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}