《表6 Adaboost模型的混淆矩阵》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于集成学习的2型糖尿病患者降糖药用药方案智能分类探讨》
3模型预测准确率及一致性利用训练数据集建立Adaboost分类模型,然后将测试数据集输入训练好的模型中得到分类预测结果,根据预测结果的混淆矩阵计算分类准确率和Kappa系数。两个模型输出的混淆矩阵如表5、表6所示,在四类用药方案的测试数据集中,单一CART决策树模型正确识别的样本数分别为620、136、59、4;而Adaboost模型正确识别的样本数为625、138、72、5。由此可知,Adaboost算法生成的强分类器模型对四类用药方案的识别准确率均有所提高。根据以上混淆矩阵,分别计算得两个模型的准确率和Kappa系数,即Adaboost模型准确率为64.2%,Kappa系数为0.36;单一CART决策树模型准确率为62.6%,Kappa系数为0.32。可见,Adaboost模型的总体准确率和Kappa系数均优于CART模型,进一步证明了Adaboost在2型糖尿病降糖用药方案决策支持方面的有效性。
| 图表编号 | XD00107658700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.28 |
| 作者 | 宋亚男、金昕晔、张颖、陈康、应俊、薛万国、母义明 |
| 绘制单位 | 解放军总医院医疗大数据中心、解放军总医院第一医学中心内分泌科、解放军总医院第一医学中心眼科、解放军总医院第一医学中心内分泌科、解放军总医院医疗大数据中心、解放军总医院医疗大数据中心、解放军总医院第一医学中心内分泌科 |
| 更多格式 | 高清、无水印(增值服务) |





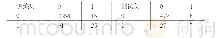
{kind=link}