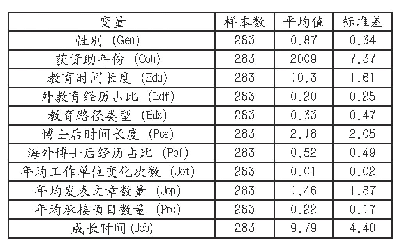
《表4 描述性统计结果:基于Wavelet-LSTM模型的北京空气污染物浓度预测》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于Wavelet-LSTM模型的北京空气污染物浓度预测》
由于LSTM模型通过核函数可以对输入变量与预测目标之间的高维度非线性关系进行高效的表达,因此使用合适的高维信息作为输入变量可以更有效精确描述信息特征,说明模型预测能力在很大程度上依赖于模型设计中输入变量的选择。本文将输入变量数据通过小波分解变换提升为高维数据集,更加全面、有效地表示数据变化趋势,从而提高预测精度。使用Matlab工具箱将6项空气污染物(PM10、PM2.5、NO2、SO2、O3、CO)分别利用小波分解变换得到的低频近似信息和高频信息构成新的预测数据集作为LSTM模型的输入变量。小波分解变换结果如图4所示,D=(d1,d2,d3)为高频信息组,A=(a3)为低频信息组。原始数据通过小波分解变换后可以得到相较于原数据具有更稳定的方差和较少的奇异值点的子序列数据,可以更加有效、准确地表达原信号信息[30]。LSTM模型使用小波分解变换得到数据作为新的训练数据进行实验,实验结果平均MAPE达到10.71%(表3),与使用传统LSTM模型的预测结果相比,MAPE降低1.91%,模型对于不同预测目标MAPE的方差明显变小,稳定性能明显提升。通过小波分解变换可得到作为数据变化趋势的低频信息子集,LSTM预测模型对于污染物浓度数据的学习程度得到加深。使用小波分解变换处理输入变量后,在预测不同目标污染物情况下,预测精度高,稳定性表现良好,具体实验结果描述性统计如表4所示。根据图5中2017年预测预测结果可知,该模型对可吸入颗粒物(PM10)的异常点的预测具有较强的适用性,而对于SO2的异常值预测能力表现较差。说明由于数据数值和单位的差异,将影响污染物浓度预测模型的泛化能力。
| 图表编号 | XD00103294600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.01 |
| 作者 | 刘炳春、来明昭、齐鑫、王辉 |
| 绘制单位 | 天津理工大学管理学院、天津理工大学管理学院、天津理工大学管理学院、天津理工大学管理学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}