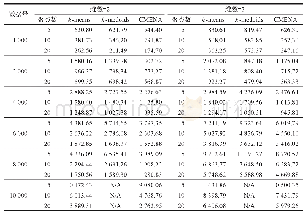
《表2 采取有放回抽样,θ=10 000,随机模拟重复10 000次时,6个估计量的偏倚和均方根误差》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:括号中数值为对应的均方根误差.
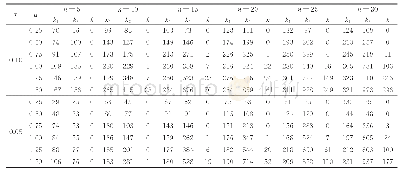
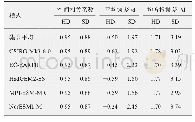
此外,通过表3中无放回抽样情况下各估计量的模拟结果可以发现,当样本容量n≥500时,的估计值与真值θ之间的偏倚最小,均方根误差也是6个估计量中最小的,这更直观的说明了是无放回抽样时θ的最小方差无偏估计.在模拟研究中我们也留意到,当重复次数R=10 000,n=5时,与θ之间的偏倚较大,看似不符合无偏估计的理论结果.利用中心极限定理,我们估算出总体容量θ的置信度为95%的置信区间为(9 929.49,10 035.09),其包含真值10 000,这说明在模拟中出现这样的偏倚是可以接受的.当重复次数增加时,的偏倚会越来越接近0.另一方面,虽然无偏估计是在无放回抽样的条件下推出的,但通过表2也可以看出,它在有放回抽样时的表现也是相当不错的.
| 图表编号 | XD00100737400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 李亚男、王昱泉、陈国蓝、胡跃清 |
| 绘制单位 | 复旦大学生命科学学院生物统计学与计算生物学系、复旦大学生命科学学院生物统计学与计算生物学系、复旦大学生命科学学院生物统计学与计算生物学系、复旦大学生命科学学院生物统计学与计算生物学系 |
| 更多格式 | 高清、无水印(增值服务) |


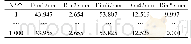
{kind=link}