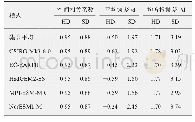
《表1 采取有放回/无放回抽样,θ=10 000,n=10时,6个估计量的偏倚和均方根误差》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:括号中数值为对应的均方根误差.
限于篇幅,我们只展示θ=10 000的随机模拟结果.表1(见第556页)为有放回抽样和无放回抽样下,n=10,重复次数R分别取不同值时各估计量的模拟结果.从表中可以看出,重复次数R=1 000时,各估计量的偏倚较大,这说明了n较小时,如果重复次数不是足够大,模拟结果难以体现各估计量的特性.R增加到10 000或以上时,各估计量的均方根误差均趋于稳定,偏倚也接近真实值.
| 图表编号 | XD00100737300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 李亚男、王昱泉、陈国蓝、胡跃清 |
| 绘制单位 | 复旦大学生命科学学院生物统计学与计算生物学系、复旦大学生命科学学院生物统计学与计算生物学系、复旦大学生命科学学院生物统计学与计算生物学系、复旦大学生命科学学院生物统计学与计算生物学系 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}