《表1 线程布局:基于OCT的手指皮下组织的三维可视化》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
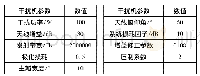
GPU中需要完成的主要有数据截取、插值、减直流、FFT变换、取模和取对数这些计算,将它们改写成Kernel函数,一个Kernel函数对应一个线程网格(Grid),线程网格由大量线程块(Block)组成,线程块由大量线程(Thread)构建。具体的线程布局如表1所示,Grid(x,y,1)用于定义Grid的维度和尺寸,即一个Grid有多少个Block,Block (x,y,z)用于定义Thread的维度和尺寸,即一个Block有多少个Thread。在线程布局时,定义的Grid和Block都是一维的,线程中的线程数量都是一个束(Warp)的整数倍,即32的整数倍,因为GPU的执行是以Warp为单位进行调度,如果Block中的线程数不设为32的整数倍,则最后一个Warp中的部分线程是没有用的。线程布局完成后,每个数据元都有唯一对应线程和线程块索引。其中,FFT运算部分采用CUDA自带的CUFFT库实现,首先用CufftHandle plan定义一个句柄plan,然后利用Cufftplan1d函数创建一个一维快速傅立叶变换句柄,设置好plan后,运行CufftExexcC2C函数,即可在GPU上完成FFT运算,由于plan可以根据输入数据的大小预先配置好内存和计算资源,在运算时处理器可达到最佳性能。具体程序设计如下:1)CPU上读取OCT采集到的原始bin数据到内存;2)利用CUDA中的cudaMalloc函数在GPU上分配显存,由于笔者将300个B-SCAN依次在GPU中并行处理,故分配的显存大小由一个B-SCAN的数据量决定;3)利用CUDA中的cudaMemcpy函数将CPU上准备好的数据拷贝至显存,每次拷贝的数据量大小为一个B-SCAN的数据量;4) CPU上调用Kernel函数,GPU上执行并行计算,完成数据截取、插值、减直流、FFT变换、取模和取对数计算,其中,FFT运算部分采用CUDA自带的CUFFT库来实现;5)利用CUDA中的cudaMemcpy函数将GPU显存中的结果拷贝至CPU,300个B-SCAN的计算结果存储在三维纹理数组中,得到一个体数据,为后文的三维可视化做准备。
| 图表编号 | XD0098775000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.25 |
| 作者 | 蒋莉、黄佐昌、王海霞、陈朋 |
| 绘制单位 | 浙江工业大学信息工程学院、浙江工业大学信息工程学院、浙江工业大学信息工程学院、浙江工业大学信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}