《表3 实验数据集划分:Transformer-CRF词切分方法在蒙汉机器翻译中的应用》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《Transformer-CRF词切分方法在蒙汉机器翻译中的应用》
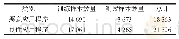
模型训练的数据集使用内蒙古工业大学蒙汉翻译课题组的项目《基于深度学习的蒙汉统计机器翻译的研究与实现》构建的120万句对蒙汉平行语料库和内蒙古大学开发的67 288句对蒙汉平行双语语料,另外使用了由一些专有名词组成的词典库,用来校正我们的蒙汉翻译系统,蒙汉平行词典库包含11 160组地名库、15 001组人名库、2 150组农业名词库、308 714组医学名词、5 000组物理名词。实验数据采用留出法进行语料的划分。留出法主要将数据集语料分为三个部分:训练集、验证集和测试集。模型的数据集划分如表3所示。
| 图表编号 | XD0091823700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 苏依拉、张振、仁庆道尔吉、牛向华、高芬、赵亚平 |
| 绘制单位 | 内蒙古工业大学信息工程学院、内蒙古工业大学信息工程学院、内蒙古工业大学信息工程学院、内蒙古工业大学信息工程学院、内蒙古工业大学信息工程学院、内蒙古工业大学信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}