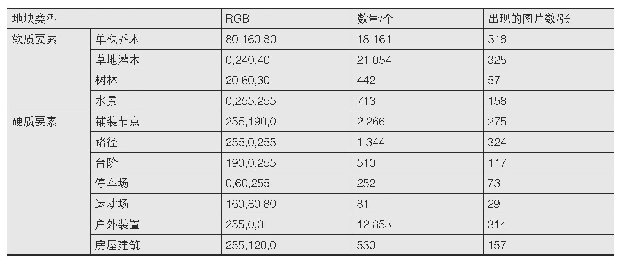
《表1 DBLP数据中各类数据数量》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《一种基于层次分割和聚合的大数据流水线任务处理方法》
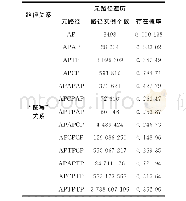
某次实验结果如错误!未找到引用源。所示,结果表明,在使用本文方法处理数据的过程中,由于P、IC类型的数据量较少,最先处理完毕并写入Hive数据库,A、IP类型的数据量较多,最后处理完毕写入Hive数据库,同时任务处理的无序性与并行性导致P、IC类型的数据量虽然比B、MT类型的数据量多,但比B、MT类型的数据先处理完毕。与Apache NiFi传统处理方法处理DBLP数据相比,传统方法写Hive数据库的次数总计68525次,本文方法写Hive数据库的次数总计8次,最终导致本文方法处理DBLP数据的速率是Apache NiFi传统处理方法处理速率的7倍多。
| 图表编号 | XD0091303900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.20 |
| 作者 | 陈天乐、蒲军、朱小杰、崔文娟、冯伟华、王锐、杜一、周园春 |
| 绘制单位 | 中国科学院计算机网络信息中心、中国科学院大学、中国科学院计算机网络信息中心、中国科学院大学、中国科学院计算机网络信息中心、中国科学院计算机网络信息中心、中国烟草总公司郑州烟草研究院、中国烟草总公司郑州烟草研究院、中国科学院计算机网络信息中心、中国科学院计算机网络信息中心 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}