《表4 两种平台三种实现方案对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于分数阶傅里叶变换的水下航行器LFM回波检测算法的GPU优化实现》
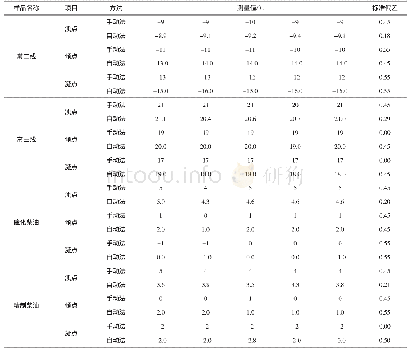
表4给出了NB=3,NP=81条件下处理一窗数据时几种方案执行时间。在桌面级平台上,与CPU实现方案相比,GPU方案能获得超过9倍的性能加速。对于计算复杂度较低的步骤如BF_IN步骤,GPU方案仅获得约2.33倍性能加速。加速效果不明显,原因为核函数的启动具有较大而相对固定的时间开销,当计算任务的计算复杂度较低时,核函数启动时间开销占比较大且不可忽略。另外,C_CONV步骤的计算复杂度约5.6 GFloats,GPU方案实现该步骤的计算吞吐量约243 GFlops,获得约10倍性能加速,这充分体现了GPU在处理大规模并行计算任务时的优势。将GPU并行程序移植到嵌入式平台上,执行时间约89 ms,小于UUV平台半窗采集数据的更新时间,满足实时性需求。
| 图表编号 | XD0091077200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.20 |
| 作者 | 詹飞、马晓川、吴永清、王磊、杨力 |
| 绘制单位 | 中国科学院声学研究所、中国科学院大学、中国科学院声学研究所、中国科学院大学、中国科学院声学研究所、中国科学院大学、中国科学院声学研究所、中国科学院声学研究所 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}