《表1 0 RICSA-KELM模型在KDD99数据集上选出的特征子集》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于ReliefF和改进乌鸦搜索优化的并行入侵检测方法》
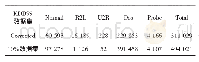
为了更全面地研究ICSA的特征选择过程,探究到底是哪些特征参与了KELM模型的训练,给出了RICSA-KELM在KDD99数据集上10-CV所选中的特征集合,如表10所示。入侵检测数据集共包含41个特征,但并非所有的特征都对分类准确率有帮助,特征选择提高了分类精度,正如表5和6所示的结果一样。从图3统计特征被选择的频率可知,其中最重要的特征有F1、F2、F3、F4、F10、F20、F23、F24、F38和F39(共10个),这些特征出现的频率要明显高于其他特征(出现频率次数大于等于7),分别对应KDD99数据集的特征项为duration(1)、protocol_type(2)、service(3)、flag(4)、hot(10)、num_outbound_cmds(20)、count(23)、srv_count(24)、dst_host_serror_rate(38)、dst_host_srv_serror_rate(39)。进一步研究这些与网络入侵相关的因素,为入侵检测提供更有力依据,从而帮助专家进行及时应对处理。为了验证并行模型的性能,将并行模型与串行模型进行比较。表11给出了并行模型和串行模型在KDD99数据集上的测试结果。从表中可以看到,两个模型在四个性能指标上的结果非常相近,它们的差别在于交叉验证过程数据集的随机选择。但在运行时间上串行模型ICSA-KELM的平均时间大约是并行模型RICSA-KELM的3倍。从图4也可看到,在每一折过程中并行模型花费的CPU时间要远低于串行模型,这表明提出的方法从并行算法获益,弥补传统串行算法耗时过多的问题,极大提高了算法计算效率。
| 图表编号 | XD0090326600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 马超 |
| 绘制单位 | 深圳信息职业技术学院数字媒体学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}