《表1 目标函数:图形处理器维度层并行粒子群优化算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文实验系统环境为Window 7系统,开发工具为Visual Studio 2015。算法的串行部分通过C++实现,算法的GPU执行通过CUDA C实现。串行程序在INTEL XENO3.0 GHz处理器上运行,内存大小为16 GB,并行程序在NVIDIA GTX580上执行。该GPU为费米架构,一共有16个SM,每个SM包含32个SP,每个SP的主频为1.544GHz。GPU的全局内存大小为1.5 GB。采用如表1所示的2个基准函数对算法进行性能测试。这2个函数的最小值都为0。为验证方法的有效性,算法的串行执行和并行执行采用相同的粒子个数和目标函数维度。由于粒子群算法的随机性,本文算法结果采用执行20次后取平均值的方式。本实验中,当求解目标函数的误差小于10-4时,算法终止。
| 图表编号 | XD0079759100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.15 |
| 作者 | 符锡成 |
| 绘制单位 | 海南科技职业学院信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |

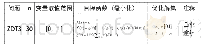




{kind=link}