《表1 预处理结果:基于Hadoop和Python的高校图书馆个性化服务的研究与应用》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于Hadoop和Python的高校图书馆个性化服务的研究与应用》
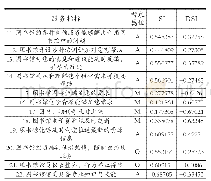
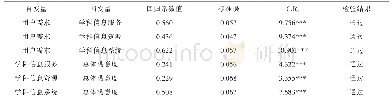
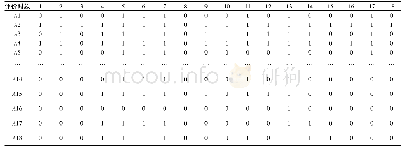
本文采集全校8 304名在读学生的借阅数据,采用增量追加,编写Shell批量命令到文件SqoopTime.sh,设置每天执行一次,保持数据的同步。采集到Hadoop平台的数据,利用Hive中提供了类似SQL的完整查询语句,进行预处理,处理结果如表1所示,该表按分类号分组统计了每个学生的阅读量。
| 图表编号 | XD0078263600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.03.25 |
| 作者 | 刘哲 |
| 绘制单位 | 北京中医药大学信息中心 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}