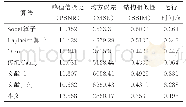
《表5 阈值选择及模型在实际应用中的性能》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
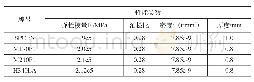
接下来,我们探究在实际应用中,选取这些阈值的模型是否也能够有相同的表现.我们使用2016年数据集来模拟实际应用的场景.同样,考虑到问题处理结果的稳定性,除去数据集中最后一年的问题报告,为了测试已有模型在未来应用中的性能,选取2013年数据集收集1年之后所提交的新报告,即从2016年数据集中节选2014年1月~2015年1月的1年间提交的已解决的问题报告.实验结果见表5,从中可以看到,60%分位点的阈值已不具有最佳的分类表现,并且在新的数据集上无论选取哪个阈值,模型的F1-score都不如实验阶段的结果.为了探索其中的原因,我们首先比较了自变量NR在训练数据和实际应用数据中的均值和平均数,它们分别从40和15上升到831和43,发生了较大的改变;其次.我们使用新增数据对模型重新训练,结果表明,报告者近期提交报告的数量的解释度远高于使用2013年数据训练的模型(见表6),也就是说,模型预测能力的下降是因为实验中的模型参数已不再适用于新的应用场景.而模型解释度的提升反映出,随着时间的推移而新增的数据出现了新的特点,我们推测在2013年之后,Mozilla社区的一些实践方法的优化措施,例如Bugzilla问题报告引导程序的改进有效地训练了新手完成问题报告的能力.
| 图表编号 | XD0073049500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.01 |
| 作者 | 朱家鑫、周明辉 |
| 绘制单位 | 北京大学信息科学技术学院软件研究所、高可信软件技术教育部重点实验室(北京大学)、中国科学院软件研究所软件工程技术研究开发中心、北京大学信息科学技术学院软件研究所、高可信软件技术教育部重点实验室(北京大学) |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}