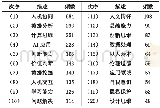
《表3 TalkingData数据集中用户行为排在前20名的用户信息》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于经验分布和KL散度的协同过滤推荐质量评价研究》
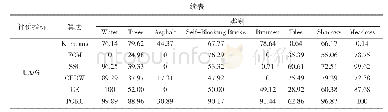
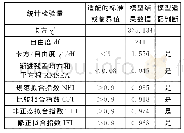
在进行实验时,由于数据量庞大,为了推荐实际结果的可用性起见,本文对上述数据进行了筛选(表3)。在原始数据中,用户每次对App产生行为时就会自动生成一次事件,这些行为包括利用App接入互联网、使用新的App、删除旧的App等等。该事件中包含着用户的行为时间信息(具体到秒为单位),用户此时正在使用的App(包括了后台开启行为)。在对用户的行为次数进行了统计、排序之后,为了尽量减少数据稀疏性带来的影响,本文选择了行为次数在500~1 000的总计2 020名用户作为实验数据集。其原因是这些用户的行为次数处于所有用户行为次数的中间,行为较为规律且相对比较稳定,既不会固守已经使用的App不变,也不会进行盲目跟风使用,数据相对来说具有代表性。而这2 020名用户中,有250名用户使用的App数量小于10,对于App的推荐来说,这些用户本身的信息不足以产生合理的推荐,所以剔除这250名用户,选择余下的1 770名用户作为本文的实验对象。对这1 770名用户的个人信息、动态行为进行汇总后,作为本文研究的实验数据集。
| 图表编号 | XD0067696500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.01 |
| 作者 | 张文、姜祎盼、张思光、崔杨波、杜宇航 |
| 绘制单位 | 北京化工大学经济管理学院、北京化工大学经济管理学院、中国科学院科技战略咨询研究院、北京化工大学经济管理学院、北京化工大学经济管理学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}