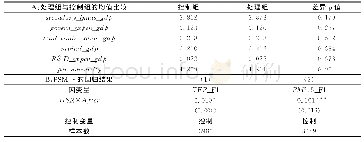
《表6 健康权益可及性对农民工城市劳动供给影响的倾向得分匹配估计结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《健康权益可及性与农民工城市劳动供给——来自流动人口动态监测的证据》
注:*、**、***分别表示通过显著性水平为10%、5%和1%的统计检验;括号内汇报对应系数值的标准误,其中K近邻匹配使用自助法获得标准误,马氏匹配和偏差校正匹配使用Abadie and Imbens(2006)的异方差稳健标准误。
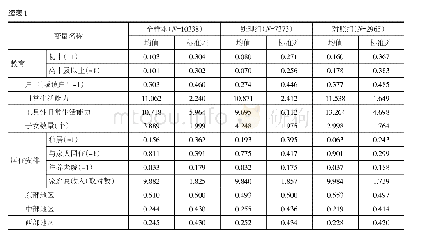
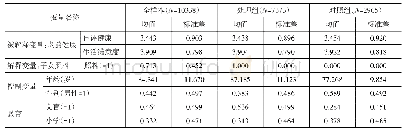
作为与熵均衡匹配估计结果的比较,本文使用其它几种倾向得分匹配方法(PSM)检验健康权益可及性对农民工城市劳动供给的影响。首先利用近邻匹配法(K=1和K=4)和马氏匹配法将处理组和控制组加以配对,并估计两组个体之间的平均差距。以健康档案对周工作小时的影响为例,图2绘制了基于K=4近邻匹配法得到的匹配前后处理组和控制组的倾向值得分的概率密度分布情况,可发现,匹配之前两者的倾向值得分的概率分布存在显著差异,匹配之后趋向重合,说明倾向得分匹配的效果比较理想。同时,考虑到上述匹配方法在第一阶段估计得分时具有较强的主观色彩,非精确匹配也存在偏差,进一步使用Abadie and Imbens(2011)的偏差校正方法实现匹配估计,该方法通过在处理组或控制组内部进行二次匹配,可得到异方差条件下的稳健标准误。表6展示了以上几种匹配方法的估计结果,可发现基于近邻匹配法和马氏匹配法估计的健康权益可及性对农民工城市劳动供给的处理效应,与熵均衡匹配估计结果相比略有分歧,而经过偏差校正匹配后的处理效应与熵均衡匹配估计结果基本吻合,这反映出熵均衡匹配在控制样本估计的选择偏差上具有一定优势。
| 图表编号 | XD0063509000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.30 |
| 作者 | 邓睿 |
| 绘制单位 | 西南政法大学经济学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}