《表3 训练集中Single-Pass聚类的实验结果Tab.3 Experimental results of Single-Pass clustering in the training set》下
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
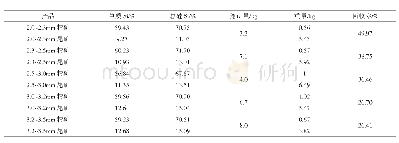
从表1和2中可以看出在训练集上基于词对的改进方法明显要优于传统的层次聚类方法.传统方法F1取最优值时,其聚类的话题个数要远大于实际话题个数,其聚类话题个数越接近实际话题个数效果越差;而改进的方法不仅将F1的最优值从0.851提升到0.901,而且F1取最优值时聚类话题个数和实际值很接近,只要不低于实际话题个数,其F1值就不会有大的变化.这是由不同话题内部文本间相似度分布不一致造成的.传统的聚类方法在取得最优值时,仍然存在一部分文本之间相似度较低的话题欠拟合;但是一旦降低阈值,又会造成另一部分话题过拟合.此时欠拟合的话题会有较高的P值和较低的R值;而过拟合的话题则有较高的R值和较低的P值,且整个话题集的F1值低于其P和R值.从表1中可以看到当阈值低于最优阈值时,其F1值要明显低于其P和R值.而对于改进的方法(表2),即使阈值低于最优阈值,其F1和P、R值间相差也不大.这说明改进的方法有效地解决了不同话题内部文本间相似度分布不一致的问题.从表3和4可以看出,虽然Single-Pass聚类和自适应K-means聚类在该数据集上的效果要优于传统层次聚类方法,但是本文中提出的基于词对的改进层次聚类方法取得了更好的结果.图2的结果也说明在聚类得到话题个数相同的前提下,基于词对的改进方法是最好的方法.
| 图表编号 | XD0044623400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.03.28 |
| 作者 | 张文博、米成刚、杨雅婷 |
| 绘制单位 | 中国科学院新疆理化技术研究所、中国科学院大学计算机科学与技术学院、新疆民族语音语言信息处理实验室、中国科学院新疆理化技术研究所、新疆民族语音语言信息处理实验室、中国科学院新疆理化技术研究所、中国科学院大学计算机科学与技术学院、新疆民族语音语言信息处理实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}