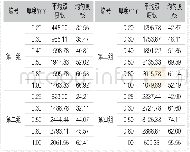
《表5 测试集中4组模型的实验结果Tab.5 Experimental results of four model in the test set》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
从表5可以看出在测试集上,虽然由于数据集分布不一致造成所有模型精度都大幅下降,但是基于词对的改进方法仍然取得了最高的F1值;同时聚类得到的话题个数(79)也比其他方法更接近实际的话题个数(49).因此虽然在本文中基于词对的改进方法是通过阈值来结束话题聚类,但是实际上由于该改进方法取得最优值时,其结果和实际话题个数相近的优点,所以该话题聚类方法的终止条件完全可以改成:当聚类的话题个数达到事先确定的NT值即停止聚类.这样在一些可以事先估计话题个数的情况下,就可以不通过阈值就得到较好的结果.
| 图表编号 | XD0044623300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.03.28 |
| 作者 | 张文博、米成刚、杨雅婷 |
| 绘制单位 | 中国科学院新疆理化技术研究所、中国科学院大学计算机科学与技术学院、新疆民族语音语言信息处理实验室、中国科学院新疆理化技术研究所、新疆民族语音语言信息处理实验室、中国科学院新疆理化技术研究所、中国科学院大学计算机科学与技术学院、新疆民族语音语言信息处理实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}