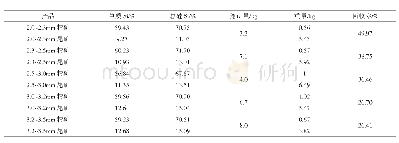
《表3 藏语-汉语机器翻译研究的实验结果Tab.3 Experimental results of Tibetan-Chinese machine translation》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
分析近几年关于小语种机器翻译的研究,一些效果较好的藏语-汉语翻译研究如表3所示,其中李亚超等[17]使用迁移学习的方法,利用规模为10万的藏语-汉语平行语料库以及规模为125万的英语-汉语平行语料库,首先使用英语-汉语的语料训练一个基线NMT模型,再使用训练得到的模型参数直接对藏语-汉语的基线NMT模型进行初始化,实验结果显示该方法相比SMT方法的BLEU值提高了3个百分点.该方法的特点是简单并且具有语言无关性,但是问题在于直接迁移预训练得到的参数对于捕获特定小语种的语言学信息是存在瓶颈的,而本文中提出的方法可以从两种语言的单语语料库中学习到额外的语言学信息,从而有利于获得更好的翻译结果.
| 图表编号 | XD0044622100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.03.28 |
| 作者 | 陆雯洁、谭儒昕、刘功申、孙环荣 |
| 绘制单位 | 上海交通大学电子信息与电气工程学院、上海交通大学电子信息与电气工程学院、上海交通大学电子信息与电气工程学院、上海交通大学-上海嵩恒信息内容分析技术联合实验室、上海交通大学-上海嵩恒信息内容分析技术联合实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}