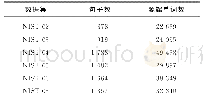
《表2 实验相关数据统计Tab.2 Statistics of experimental related data》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
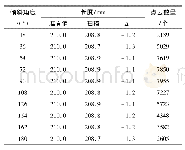
使用语言数据联盟(Linguistic Data Consortium,LDC;www.ldc.upenn.edu)中抽取的1.25×106句中英平行句对作为训练集对NMT模型进行训练,其中包含了8.09×107个中文词语和8.64×107个英文单词.另外,将国家标准与技术研究所(NIST)的NIST06数据集作为开发集,NIST 02,03,04,05,08数据集(每个数据集包含4个目标译文)作为测试集进行模型评测,具体的实验相关数据的统计情况如表2所示.
| 图表编号 | XD0044620300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.03.28 |
| 作者 | 谭新、邝少辉、张龙印、熊德意 |
| 绘制单位 | 苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}