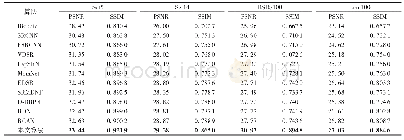
《表4 各模型在20Newsgroups的性能比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了对比提升策略在文档分类方面的效果,我们使用了与ClassRBM模型一样的数据集20Newsgroups,它收集了不同时期的新闻文档,包含11 269条训练数据及标签,7505条测试数据及标签组成,共20类新闻。实验时,将原始训练数据分成9578条数据的训练集和1691条数据的验证集。由于数据集包含的词比较多,我们仅选择了出现频率最大的5000个词作为输入数据的维度。分类结果见表4。从表中的数据来看,采用不同阈值的提升策略,其在文档分类的性能上高于ClassRBM、SVM、RBM+NNet和Random Forest。这些模型的实验数据来自文献[1]的实验结果。
| 图表编号 | XD0040523100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.16 |
| 作者 | 尹静、闫河 |
| 绘制单位 | 重庆理工大学计算机科学与工程学院、重庆理工大学计算机科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}