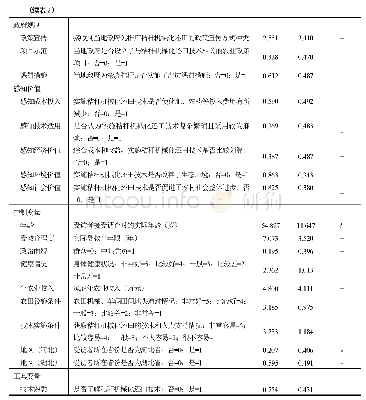
《表2 特征设置集合及描述说明》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《CRFs字角色标注方法在中文附加关键词抽取中的应用研究》
特征依赖于特定的训练语料,其作用在于扩展语境特征,提高测试阶段的准确率。特征序列的构建是否恰当、准确,将对机器学习的效果产生一定程度的影响。特征的选择主要由笔者对于题名与其他原文信息的观察于统计所得,可以分为三个方面:一是词的角度。题名往往包含多个词语,且关键词的词性往往集中在名词、动词、形容词等实词,针对词语的构成与性质,笔者使用中国科学院计算技术研究所汉语词法分析系统(ICTCLAS),按照北京大学标注一级标注进行分词与词性标注,由此提出构词特征(W)与词性特征(C),如词性未识别出记为0,例如“马克思主义”一词,根据词的构造,构词特征序列为“TZZZW”,而词性为名词(N),则词性特征序列为“NNNNN”。二是字的角度。题名中存在着包含中外名人姓名的情况,也经常以关键词全部或部分的形式呈现,例如“毛泽东”“墨菲定律”“邓小平理论”等,对此设置了字的姓氏特征(X)与音译特征(Y);根据《现代汉语常用字表》引入字的级别特征(J);根据字在2014年CSSCI题名中出现的频次加以分类,提出频次特征(S);根据“六书”的对字的分类提出字类特征(L),其中转注字与注假字归为其他一类;字性特征(D)使用ICTCLAS系统对题名中的每个字单独进行北大标注一级标注得来,指每个汉字都有其独特的词性倾向,未识别记为0。三是其他信息。原文信息集合还提供了文章的中图类号及期刊等信息,由此可以引入文章中图特征(T)和期刊类别(Q)。上述的10个特征及相应描述如表2所示,具体约束效果将在后续的实验中逐步验证。
| 图表编号 | XD0039045100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.02.28 |
| 作者 | 张海潮、王昊、唐慧慧、薛蔚 |
| 绘制单位 | 南京大学信息管理学院、江苏省数据工程与知识服务重点实验室、南京大学信息管理学院、江苏省数据工程与知识服务重点实验室、南京大学信息管理学院、江苏省数据工程与知识服务重点实验室、南京大学信息管理学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}