《表1 词向量模型比较分析》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
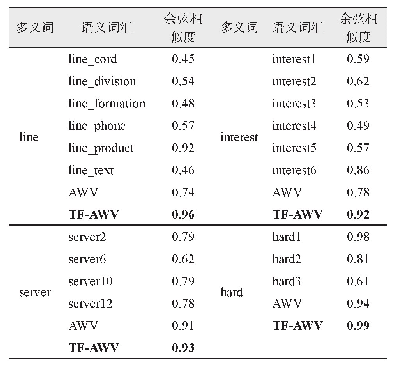
2) 词向量模型及其比较分析:在分词的基础上,将人类可以理解的文本信息,转化为计算机能够理解的信息,成为了自然语言处理中的一项关键技术。2013年Mikolov等提出了Word2vec模型[16]可以快速而高效地训练词向量,体现词与词之间的关联度关系。Word2vec模型包含两种基于神经网络的训练模型,一是CBOW(Continue Bag of Word)模型,另一种是Skip-gram模型。CBOW模型是通过上下文来预测当前词而Skip-gram模型则是通过当前词来预测其上下文。两种相反的训练方法对应了不同的数据需求。CBOW在小型语料库中表现良好,而Skip-gram则在大型语料库表现更为出色。由于两种算法在针对大量数据的时候,参数训练的规模都空前巨大,极耗费时间。因此Mokolov引入了两种优化算法Hierarchical Softmax和Negative Sampling。两种训练算法与两种优化算法相结合可以得到四种框架。CBOW和Skip-gram的对比分析如表1所示。
| 图表编号 | XD0039036700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.30 |
| 作者 | 黄微、刘熠、孙悦 |
| 绘制单位 | 吉林大学管理学院、吉林大学管理学院、吉林大学管理学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}