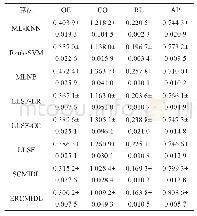
《表2 明清宫廷服饰图案数据集实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了验证算法有效性,本文与几种经典的多标签标注算法进行了对比实验,包括ML-KNN(multilabel KNN)[7],Rank-SVM[9],MLNB(multi-label naive Bayes)[51],同时,使用了基于特征选择算法LLSF(learning label specific features)[52]的BR(binary relevance)和CC(classifier chains)算法.MLNB算法首次将特征选择技术运用于多标签标注中,其中包含两个阶段的特征选择策略,第1阶段使用PCA消除不相关和冗余特征,第2阶段利用遗传算法将核实的特征子集进行分类.同时使用基于朴素Bayes的多标签学习算法.LLSF算法是一种线性分类算法,它对每一个标签训练一个回归系数,引入L1范数正则化使算法具有特征选择的作用,同时根据标签相关性降低回归系数的相关性.LLSF-BR算法是根据LLSF算法对数据特征进行选择,然后再使用BR算法进行多标签标注,LLSF-CC则是再使用CC算法进行多标签标注.本文实验参数设置为λ1=0.01,λ2=0.01,λ3=0.001,γ=0.05,明清宫廷服饰图案数据集与传统地毯图案数据集字典原子数为25,传统民族服饰图案数据集字典原子数为30.三个数据集上的实验结果如表2~4所示.部分图像的标注结果如图5所示.
| 图表编号 | XD0039018800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.02.20 |
| 作者 | 赵海英、陈洪、贾耕云、郑桥、王绍杰 |
| 绘制单位 | 北京邮电大学世纪学院移动媒体与文化计算北京市重点实验室、北京邮电大学网络技术研究院、北京邮电大学世纪学院移动媒体与文化计算北京市重点实验室、北京邮电大学网络技术研究院、北京邮电大学网络技术研究院、北京邮电大学网络技术研究院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}