《表3 复旦大学中文语料库中特征维度2500时不同类别的SVM分类宏F1值》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
%
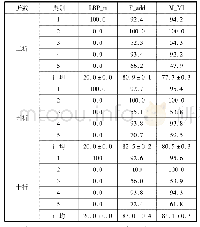
在网易新闻语料库和复旦大学中文语料库中,在宏F1值分别达到最大值时分析各个类别的宏F1值,如表2、表3。各个类别宏F1值差别明显,原因是不同文本长度对于结果的影响,如果文本较短,含有很多空值,使向量稀疏,造成分类结果较低。若文本含有词数较多,并含有一些类别区分度高频词语,使宏F1值较大,本文提出的方法能有效改善传统CHI和TF-IDF的缺陷,过滤掉低频词语,改善不同特征词的权重,使得分类效果更好,性能更稳定。
| 图表编号 | XD0028795700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.02.20 |
| 作者 | 宋呈祥、陈秀宏、牛强 |
| 绘制单位 | 江南大学数字媒体学院、江南大学数字媒体学院、江南大学数字媒体学院 |
| 更多格式 | 高清、无水印(增值服务) |
![表2 不同语料下实体的F1值[31]](http://bookimg.mtoou.info/tubiao/gif/QBGC202004005_05700.gif)




{kind=link}