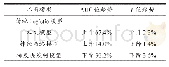
《表4 保险赔付风险预测模型的混淆矩阵》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为验证本文模型对于保险赔付风险的预测性能,选取十折交叉验证法。将全部实验数据分成10个数据子集,各数据子集均不重合,以其中9个数据集和剩余1个数据集分别为训练集和测试集。保险赔付风险预测是一个二分类问题,普遍使用的评价指标有F值与AUC值,二者是评估预测模型预测性能的指标,其值越靠近1,说明预测真实性越好。在计算这2个值时均以描述样本实际类别与模型预测类别交叉统计结果的混淆矩阵为基础。通过混淆矩阵评估预测模型的预测性能。表4为混淆矩阵针对保险赔付风险预测模型的基本结构。
| 图表编号 | XD00226950900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.11.15 |
| 作者 | 温晓楠、董立伟、朱亚培、刘艳敏 |
| 绘制单位 | 河北农业大学、北京交通大学海滨学院、河北农业大学、河北农业大学 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}