《表1 园林特征矩阵示意:园林历史研究中的量化及分析算法研究——以南京明、清杏花村地块为例》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《园林历史研究中的量化及分析算法研究——以南京明、清杏花村地块为例》
私家园林依建造基址,以及园主人身份、喜好和造园目的不同,受主持造园匠人工艺、技法以及园林时代的影响,组合后呈现丰富且复杂的园林成果。这种丰富性也使得在研究一定地域范围或时间范畴的大量对象时,陷入过于复杂而难以进展的困境。在传统研究范式中,往往通过分类研究或单类研究方法来降低复杂度,当通过分类不能降低复杂程度时,采用提取一定比例的高频特征或人为认定的经典对象进行研究。但具体的分类方法和比例则依赖经验,而这可能导致研究结果的“幸存者偏差”[4-5]。假设某地域12处园林具有如表1的特征矩阵,如果按园林四要素分类后提取最高频信息,则会得到该地域园林植物为松树、水系为自然水系这一结论;而若采用植物加水系的分类体系,则会得到该地域园林以柳树加方形水池为主要特点的结果。从样本覆盖率的角度来看,后者的覆盖样本数更大,是较为“接近准确”的规律。但事实上,大量已有研究都采用单一四要素分类后研究的范式而不是组合特征分类,而且对高频特征的提取比例也无定论,研究过程多未涉及上述复验过程。说明传统研究范式缺少针对复杂历史对象有效的研究方法。这就要求改变传统资料罗列或高度依赖研究者个体探索历史规律的研究路径,转而探索更为便捷、更高信息覆盖率的新研究方法。若能将大量历史信息量化,则可以信息特征矩阵为基础,借助各类数据分析的思路和方法,并与传统研究成果对应比较。
| 图表编号 | XD00224192300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.01 |
| 作者 | 乐志、应天慧、马群 |
| 绘制单位 | 南京林业大学风景园林学院、东南大学建筑学院、南京林业大学风景园林学院 |
| 更多格式 | 高清、无水印(增值服务) |
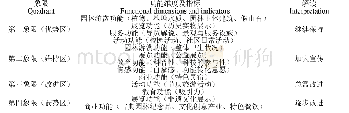




{kind=link}