《表3 micro F1测试结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
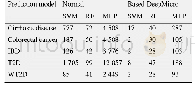
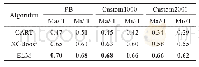
Graph Sage以及Block Sage算法使用相同的数据集作为输入,其中两算法的共同参数都保持一致。经过无监督的图表示学习之后,得到图中每个节点的embedding向量。将结果保存到文件中,在此基础上进行下游的机器学习任务。下游的机器学习任务Graph Sage和Block Sage使用的算法完全一样。因为两种算法的输出都一样,所以测试算法不需要作任何修改。首先使用线性多分类器进行无监督的学习,若干轮次之后,将算法应用到测试数据上进行测试。本文测试中,对于测试节点和训练节点的选择,Graph Sage和Block Sage算法也都完全一样。测试效果使用micro F1数值进行衡量。其中Block Sage算法在两个数据集上的划分大小均使用9,缓存池大小最大缓存块数为6,最后得到测试数据如表3所示。
| 图表编号 | XD00222752000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.05 |
| 作者 | 夏鑫、高品、陈康、姜进磊 |
| 绘制单位 | 清华大学计算机科学与技术系、腾讯微信事业群、清华大学计算机科学与技术系、清华大学计算机科学与技术系 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}