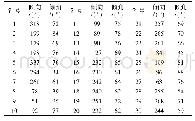
《表6 执行Facebook trace时172.19.2.172部分文件读取流》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文首先使用SWIM工具以较低的开销在实验Hadoop环境上重现上述Facebook trace,该工具依照原trace中的时间和数据大小不断向Hadoop递交job。根据需要,本实验将job执行所需的数据平均文件大小设置为32 MB,总文件数为1 501。在脚本执行完毕后,即获取到了job执行完毕后GB级别的Hadoop日志,接着使用模型对这些日志进行负载时序分析,以获取不同节点的读取时序流,部分分析结果如表6所示。根据统计结果显示,仅前1 000个job运行时间约为9 h 38 min,访问文件次数约为21 000个,足以证明文本提出的模型在复杂应用中的工作价值。
| 图表编号 | XD00222676000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.10 |
| 作者 | 苟子安、张晓、吴东南、王艳秋 |
| 绘制单位 | 西北工业大学计算机学院、西北工业大学计算机学院、工信部大数据存储与管理重点实验室(西北工业大学)、西北工业大学计算机学院、西北工业大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}