《表1 查找表的初始状态:大规模流数据处理中代价有效的弹性资源分配策略》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
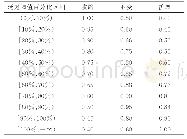
在算法2中,首先,对强化学习技术中的参数γ、ι、d赋初始值,同时,基于延迟阈值设置对查找表进行赋值,即在最高延迟阈值百分比以上,最高奖励被赋值给扩展动作;在最低延迟阈值百分比以下,最高奖励被赋值给收缩动作;在最高延迟阈值百分比以下、最低延迟阈值百分比以上,最高奖励属于无动作(第1行)。在应用中,每个操作对应1个查找表,查找表的每条记录是状态-动作对,描述了给定延迟阈值百分比区间对于不同动作的预期奖励值,可能的动作包括资源扩展,资源收缩和资源不变(没有动作)。其中,状态分为11种,即将阈值百分比从0到100划分为10份,每间隔10%为1种状态,且区间是左闭右开的。特殊地,将大于或等于100%的阈值百分比作为第11种状态。以最低延迟阈值百分比=40%、最高延迟阈值百分比=90%为例,所有查找表的初始设置相同,如表1所示。接下来,与算法1类似,计算每个操作的延迟期望值?Τi (t)、应用的延迟期望值?T和延迟违反比率LVR(第2~5行)。
| 图表编号 | XD00222495900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.01 |
| 作者 | 李丽娜、魏晓辉、郝琳琳、王兴旺、王储 |
| 绘制单位 | 吉林大学计算机科学与技术学院、长春大学计算机科学技术学院、吉林大学计算机科学与技术学院、吉林大学符号计算与知识工程教育部重点实验室、吉林大学计算机科学与技术学院、吉林大学计算机科学与技术学院、吉林大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}