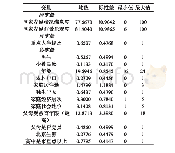
《表1 变量的描述性统计(n=2136)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
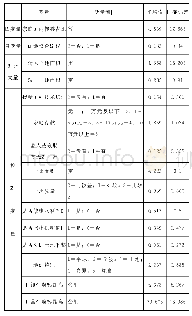
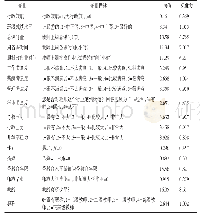
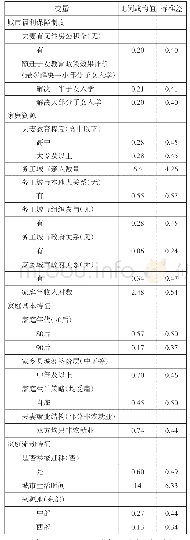
本文的控制变量主要用来计算不同被试就读重点大学的概率,进而将其匹配成两组“平衡”的、类似于随机实验的控制组和实验组,主要包括基线调查时学生的性别、民族、年龄、户口类型、家庭居住地类型、是否独生子女、家庭经济层次、家庭社会地位、父母受教育年限、父母政治面貌、是否北京生源以及高中学校类型。其中,性别(0=女,1=男)、民族(0=汉族,1=少数民族)、户口类型(0=城镇户口,1=农村户口)、是否独生子女(0=非独生子女,1=独生子女)、父母是否党员(0=父母双方都不是党员,1=父母中至少有一方是党员)、北京生源(0=非北京生源,1=北京生源)、高中学校类型(0=非市级及以上重点高中,1=市级及以上重点高中)为二分变量;家庭居住地(0=农村,1=县级,2=地级市,3=省城、直辖市)为虚拟变量;年龄、家庭经济层次(1=上层,2=中上层,3=中层,4=中下层,5=下层)、家庭社会地位(1=上层,2=中上层,3=中层,4=中下层,5=下层)、父母受教育年限(取父母中较高一方)为连续变量。变量的描述性统计如表1所示。
| 图表编号 | XD00221141900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.20 |
| 作者 | 孙伦轩、王娇 |
| 绘制单位 | 天津师范大学教育学部、天津师范大学教育学部 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}