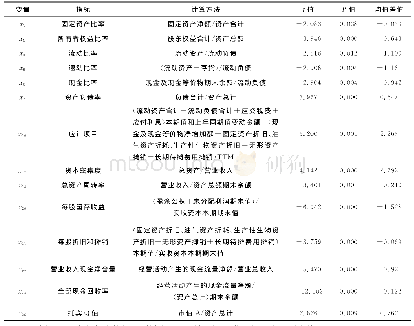
《表2 变量的描述性统计表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于Logistic模型的上市公司财务造假识别研究》
注:P值小于0.05为达到显著性水平;均值差值=疑似财务造假公司指标值-正常公司指标值。
训练集中共有618条样本数据,删除缺失值占比过多的样本,并使用K近邻法填补只有少量缺失值的样本,处理后共保留有效样本565条。根据中国证监会和沪深证券交易所认定为常规财务状况异常和其他异常状况的规则,可得到训练集样本的标签,表现为可疑造假的样本117个,表现为正常的样本448个。表2给出了财务造假可疑公司的财务指标与表现正常公司的均值差异及其检验,这表明公司在被发现财务造假前两年里,就已表现出某些比较明显的不同于正常公司的征兆。
| 图表编号 | XD00218595000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.25 |
| 作者 | 吕晨、程建华 |
| 绘制单位 | 安徽大学经济学院、安徽大学经济学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}