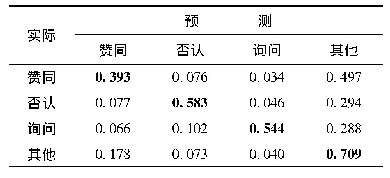
《表2 (d) SVM+Best Features困惑矩阵》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《系统功能语言学理论视角下突发公共卫生事件谣言用户立场识别研究——以COVID-19疫情为例》
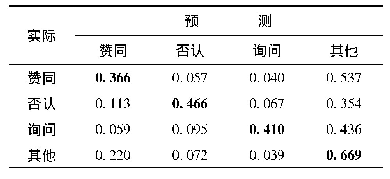
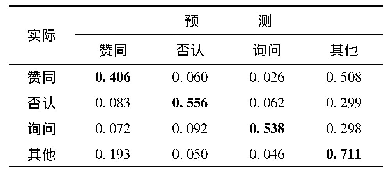
基于图6,表2(a)~(d)列出了4种分类算法与特征的最优组合实验设置下最优交叉验证结果的困惑矩阵。纵向代表实际立场,横向代表预测立场,如表2(a)中的“0.113”代表有11.3%的实际为“否认”立场的评论被预测为“赞同”。表中粗体字代表被正确分类的评论占各类别评论的比例(即召回率),最高召回率出现在SVM算法与最优特征的组合模型的“其他”立场(0.885)。4种算法中,大量其他立场的评论被误分类入“其他”立场,极少其他立场的评论被误分类入“询问”立场,这是由数据集分布不平衡性导致(“其他”立场的评论占总数的46.32%,“询问”立场的评论仅占8.69%)。即便如此,“询问”立场的召回率最高达到0.58,最低为0.41,仍高于“赞同”立场的最高召回率0.406 (“赞同”立场的评论占比20.21%,约为“询问”立场占比的2.33倍),这说明研究基于SFL理论从语篇元功能出发选取的文本中“?”数量、文本长度“Length”,从概念元功能出发选取的表达“怀疑”情绪的词语数量,从人际元功能出发选取的“Depth”等特征有力弥补了“询问”立场类别数量上的分类劣势,并进一步佐证了细粒度情感分析的有效性。平衡数据集有3种方法:欠采样和过采样以及混合采样[41],但这些方法可能破坏评论树结构,因此,优化分类效果可行性策略应该从完善实验模型设置出发,如:选择更具显著区分能力的特征、分类器参数调优、采用集成学习方法等等。
| 图表编号 | XD00212816500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.01 |
| 作者 | 王丹丹、杨艳妮、张瑞 |
| 绘制单位 | 武汉大学信息管理学院、三峡大学文学与传媒学院、湖北工业大学经济与管理学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}