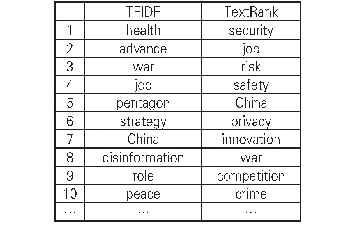
《表2 基于TFIDF算法和Text Rank算法的关键词(部分)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
对文本关键词提取分为两步,一是对数据进行处理,包括分词、去停用词等;二是利用关键词提取算法进行提取。在关键词提取上目前流行采用Text Rank算法和TFIDF算法。在获取关键句前提下,将关键词作为结点,同理可以利用Text Rank算法对关键词进行提取,具体步骤为:(1)将文本分割成整句形式,如T=[j1,j2,j3,...,jn];(2)依次将每个句子进行分词和词性标注,删除停用词,保留指定词性的词,如名词、动词、形容词,形成候选关键词;(3)构建候选关键词图G=(V,E),V为候选关键词节点集,随后利用共现关系构造两节点边,节点之间存在边且在对应词汇长度为k的窗口中共现,k为窗口大小表示最多共现k个单词;(4)重复迭代直至收敛;(5)对节点权重进行排序,合理提取。TFIDF算法在从文档中提取关键词时不仅考虑单个文档,还考虑从语料库中提取所有文档,它的核心是字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降[18]。本文结合TFIDF算法进行对比,表2展示的是TFIDF算法和Text Rank算法所提取的关键词。
| 图表编号 | XD00211518600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.10 |
| 作者 | 张誉曜、陈媛媛 |
| 绘制单位 | 新疆师范大学计算机科学技术学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}