《表1 在Market1501[6]上超参数α对比试验》
![《表1 在Market1501[6]上超参数α对比试验》](http://bookimg.mtoou.info/tubiao/gif/SJCJ202101010_06800.gif) 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
[6]
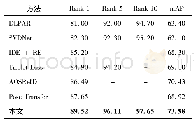
为了分析各参数在筛选学习模块中的作用,本文分别对记忆长度、记忆准确度和筛选参数进行了对比实验,实验结果分别如表1,2所示。其中筛选参数α的大小与筛选学习保留的难样本及可能噪声样本量相关,并且影响修正学习的效果,而记忆长度、记忆准确度参数相对不敏感。因此在实验中取记忆长度m=10,记忆准确度ε=0.85,以有效地分析筛选参数的影响。同时为了确保泛化能力,本文使用IDE[16]网络结构。IDE*为无噪声数据集,在表1所进行的实验中,IDE*实验结果为Rank 1 91.11,m AP79.24;在表2所进行的实验中,IDE*实验结果为Rank 1 78.14,m AP 60.38。P1指筛选学习模块,P2指修正学习模块。由表1、2可见,在含有噪声的数据集中,使用筛选学习均可以提高模型在噪声条件下的精度,α取0.3时取得最好效果,直观上是因为更大的α可以保留更多的难样本,这与筛选学习模块一致。值得注意的是,更大的α虽然会带入更多可能的噪声样本,但会在修正学习模块中被赋予更低的权重,降低噪声样本给模型带来的损耗,如果仅增大α而不使用修正学习对噪声、非噪声样本进行权重调整,精度会一定程度降低。此外,根据指数加权平均一般设置,β取0.1。
| 图表编号 | XD00208474600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.01 |
| 作者 | 唐轲、郎丛妍 |
| 绘制单位 | 北京交通大学计算机信息与技术学院、北京交通大学计算机信息与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |


![表2 在Duke MTMCre ID[5]上超参数α对比试验](http://bookimg.mtoou.info/tubiao/gif/SJCJ202101010_06900.gif)


{kind=link}