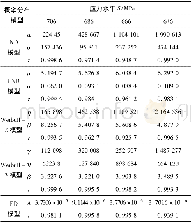
《表1 不同模型概率密度及其参数》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《多项膨胀效应模型对美国城市4~9岁儿童哮喘危险因素的分析》
模型拟合与比较传统的用于拟合计数数据最常见的模型是泊松回归(Poisson regression,POI)模型,泊松回归模型要求数据的期望均数等于期望方差。当均数与方差不等时,可以考虑使用负二项回归(negative binomial regression,NB)模型进行拟合。针对本文使用的零值较多且符合泊松分布的过离散(方差明显大于均值)复合计数资料,采用零膨胀及多项膨胀泊松分布模型进行拟合。零膨胀泊松模型(zero-inflated Poisson regression,ZIP)的基本方法是将数据集看成全0数据集A和一个服从泊松或负二项分布的数据集B组成的混合数据集,对混合计数数据建立混合概率分布,用一些特征变量对个体是否真的属于A用Logistic模型进行预测,然后将真实属于A中的个体排除后,构建泊松或负二项分布的计数模型;Logistic部分主要回答协变量影响事件发生与否的问题,泊松或负二项模型部分主要回答协变量影响事件发生次数多寡的问题。多项膨胀泊松模型(multi-inflated Poisson regression,ZKIP)则是在零膨胀模型的基础上再多加一个全n数据集C[6]。泊松、负二项、零膨胀泊松和多项膨胀模型的概率密度函数及其参数见表1。
| 图表编号 | XD00208377700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.30 |
| 作者 | 顾丹彤、林燧恒 |
| 绘制单位 | 复旦大学公共卫生学院生物统计学教研室、复旦大学公共卫生学院生物统计学教研室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}