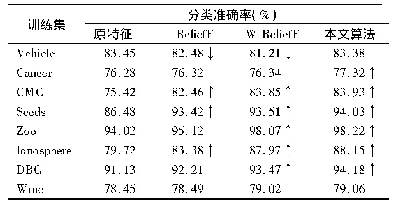
《表2 添加新特征前后准确率对比表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
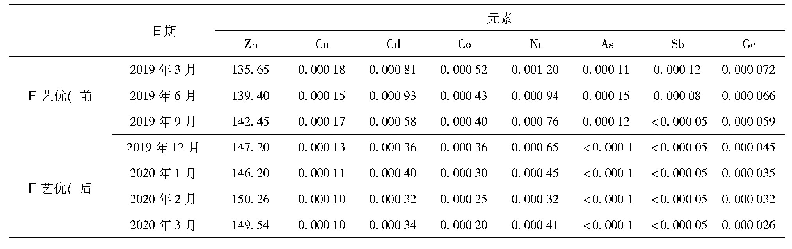
测试发现,在每次训练与识别时,算法的准确率略有不同。为降低测试结果的偶然性,重复进行30次测试。具体地,进行了30次模型训练,产生30片随机森林,取30片森林的平均准确率作为改进后算法最终的准确率,如表1所示。随机森林算法训练过程中,树的数量直接决定了模型的准确度,但当数量到达一定程度后,模型会产生过度拟合,可解释性减弱,导致准确率降低,并且会大大增加模型构建时间。经过多次测试,选定每片森林为60棵树。此外,实验计算了30次识别准确率的方差,对算法与已有算法的稳定性进行了分析,如表2所示。
| 图表编号 | XD00207973400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.01 |
| 作者 | 朱少武、孙海春、罗万杰、赵晓凡 |
| 绘制单位 | 中国人民公安大学信息技术与网络安全学院、中国人民公安大学信息技术与网络安全学院、中国人民公安大学信息技术与网络安全学院、中国人民公安大学信息技术与网络安全学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}