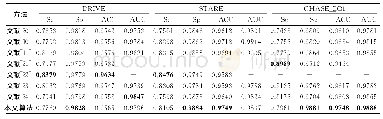
《表4 对比在DRIVE,STARE和CHASE_DB数据集中不同算法的性能》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
表4列出了在DRIVE、STARE和CHASE_DB1数据集上本文所提的分割方法与其他一些现有的分割方法进行比较.本文所提方法在DRIVE数据库的测试集中其中特异性表现较好,其他方面表现一般,文献[22]的准确率和灵敏度比本文方法分别高了0.0069和0.0619,但本文方法的特异性比文献[22]结果高了0.0049.文献[24]的AUC和灵敏度比本文方法分别高了0.0051和0.0181,但本文方法的特异性和准确率分别比文献[24]结果高了0.003和0.007.本文方法在STARE数据集和CHASE_DB1数据集的表现非常优秀.在STARE数据集中,文献[22]的灵敏度比本文方法高0.0371,但是本文方法的特异性与准确率比文献[22]的结果分别高了0.0135和0.0166.文献[24]仅在CHASE_DB1数据集的灵敏度比本文方法分别高0.0215,但在STARE数据集和CHASE_DB1数据集的其他指标效果都低于本文方法.总体来说,本文方法在不同数据集上特异性与准确率的结果相对较好,说明加入残差和卷积模块的注意力机制的算法有较强的鲁棒性.
| 图表编号 | XD00205970900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.25 |
| 作者 | 陈林、陈亚军、沈锐 |
| 绘制单位 | 西华师范大学计算机学院、西华师范大学教育信息技术中心、西华师范大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}