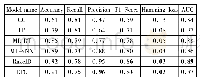
《表5 正负样本比例为1∶1时6种算法的效果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
1)多标签分类算法有效性对比。表5~表7分别给出了不同比例下6种算法的对比实验结果。从表5的实验结果发现,在正负样本为1∶1的数据集中,无论是在汉明损失、F1_Score和AUC上,Rakel D算法的性能都明显优于其他5种算法,AUC为0.87,F1_Score为0.82,汉明损失仅为0.06;从表6的实验结果来看,对于正负样本为1∶3的数据集,Rakel D和ETC这2种算法在各项评估指标上的表现相差无几。从表7的实验结果发现:对于正负比例为1∶5的数据集,ML-KNN、Rakel D和ETC这3种算法在各项评估指标上的表现差距甚微。但在建模时间上,ML-KNN算法耗时最长。3种不同比例的样本中使用ML-DT算法,精准率、F1_Score、召回率均差别不大。
| 图表编号 | XD00203363900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.01 |
| 作者 | 刘斌、李笑 |
| 绘制单位 | 陕西科技大学电子信息与人工智能学院、陕西科技大学电子信息与人工智能学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}