《表1 实验因素及水平:基于MapReduce的Apriori算法增量挖掘》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于MapReduce的Apriori算法增量挖掘》
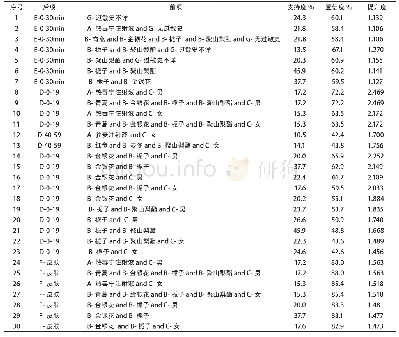
本文实验数据分别采用retail、kosarak、accidents三个真实数据集,对比情况如表1所示。其中,retail数据集是弗兰德斯地区1991—2000年间发生的交通事故记录集合,共包含340 184条事务及572条不同属性,具有数据量小、项多的特点;kosarak数据集记录了一家大型新闻网站点击流数据,该数据集包含990 002条数据,共有41 270项,具有数据量少、项数较多、数据离散等特点;accidents数据集中包含1 692 082条Web文档数据,每条数据包含5 267 656条不同属性,是一组数据集较大、数据项较多的数据集合。
| 图表编号 | XD00198038800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.31 |
| 作者 | 赵欣灿、朱云、毛伊敏 |
| 绘制单位 | 江西理工大学理学院、江西理工大学理学院、江西理工大学信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}