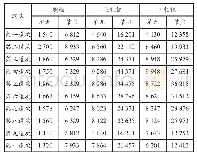
《表1 数据集的边数和顶点数》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
表1展示了WDCM和YAGO数据集中所拥有的顶点数和边数。该实验将基于聚类效果和运行时间来对算法进行测试和比较,其中算法的聚类效果是通过聚类结果对应的modularity值来进行度量的,该值的计算方法如式(1)中所示。
| 图表编号 | XD00198006200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.05 |
| 作者 | 刘东江、黎建辉 |
| 绘制单位 | 中国科学院计算机网络信息中心、中国科学院大学、中国科学院计算机网络信息中心 |
| 更多格式 | 高清、无水印(增值服务) |
表1展示了WDCM和YAGO数据集中所拥有的顶点数和边数。该实验将基于聚类效果和运行时间来对算法进行测试和比较,其中算法的聚类效果是通过聚类结果对应的modularity值来进行度量的,该值的计算方法如式(1)中所示。
| 图表编号 | XD00198006200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.05 |
| 作者 | 刘东江、黎建辉 |
| 绘制单位 | 中国科学院计算机网络信息中心、中国科学院大学、中国科学院计算机网络信息中心 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}