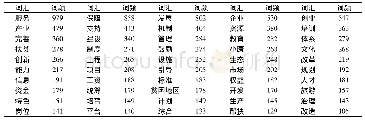
《表2 前50个高频词及词频汇总》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
资料来源:基于Python的文本挖掘处理结果
在获取文本数据的基础上,本文通过对其进行预处理为建模做好准备。由于政策内容全部为中文,因此使用Jieba库的中文分词包在Python环境下对政策文本进行分词处理操作,然后剔除无法表示文本特征的停用词。鉴于本文的研究主体为农民工就业政策,分词后文档出现频次较高的名词有“国家、北京、社会、农民工”等,量词有“第一、第二、大量、一批”等,对这次词频进行文本分析的意义较小,因此也做了清理,在此基础上,整理了前50个有效高频词,如表2所示。
| 图表编号 | XD00194577500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.10 |
| 作者 | 王霆、刘玉 |
| 绘制单位 | 中国政法大学商学院、中国政法大学商学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}