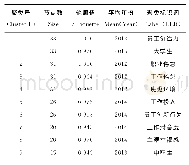
《表6 2005-2020年核心自我评价研究的关键词重要聚类及聚类标识词》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了进一步探索该领域的研究热点,对关键词共现网络图谱进行聚类分析,本文选取LLR算法(Log-Likelihood Ratio),生成自动聚类标签图谱,形成了包含170个节点、441条连线、聚类数量为16的知识图谱(如图6所示)。模块值(Q值)与平均轮廓值(S值)是经常用来衡量聚类图谱绘制效果好坏的两个重要指标,Q值在0.3及其以上说明聚类效果良好,S值在0.5及其以上表明聚类结果合理性较高。本文研究目标的Q值为0.887 5,远大于标准值0.3,表明聚类效果很显著。S值为0.513 5,略大于0.5,总体而言聚类信度检验结果良好。表6为网络聚类的具体信息,聚类号(Cluster ID)表示聚类后的编号,节点数(Size)表示聚类包含的文献的数量,聚类标签的编号越小,节点数量就越多,表明该研究越集中,热度越高。为更好地区分聚类结果中相关文献出现时间早晚的问题,本文引入平均年份加以衡量。本研究中选取节点数排名前十的聚类(如表6所示),学者对核心自我评价的相关研究主要集中在三个方面。
| 图表编号 | XD00190896600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.28 |
| 作者 | 朱萌君、常保瑞 |
| 绘制单位 | 广西师范大学教育学部、广西师范大学教育学部 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}