《表1 多模态健康数据:基于卷积与BP神经网络的健康数据分析算法设计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
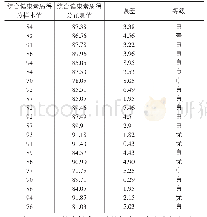
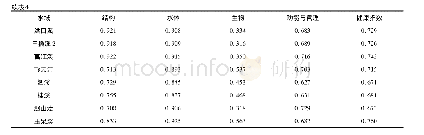
测试过程分为模型训练与测试样本验证。针对文本、数字的健康数据特征表征模型训练,首先收集一定数量病人的临床记录,通过文本数据提炼出词向量。文中共使用两个样本数据集,分别为结构化数据与非结构化数据构成的多模态数据,如表1所示。每个数据集包含200个病人的数据,其中170个病人数据作为模型训练样本数据,其余数据作为测试样本数据。使用结构化数据与多模态数据训练针对文本、数字的特征表征模型,并使用朴素贝利斯模型作为对比。测试结果如图7所示。图中,数据类型1、2、3与4分别代表仅有数字、仅有文本、仅有图像以及数字、文本、图像三者共同构成的多模态数据。从图7中可以看出,使用4种数据类型进行模型训练,文中所述的卷积神经网络模型均比朴素贝利斯模型的准确率要高。文中所述的健康评估模型对4种数据类型的健康状态评估准确率中,多模态数据的准确率最高,为84.2%;文本类型的准确率最低,为57.3%;数字与图像类型大致相同。这主要是由于文本在使用词向量进行特征提取时,词向量矩阵的容量较低所引起的。而图像本身可以通过相关算法进行数字化处理,进而与数字类型的健康数据准确率大致相同。
| 图表编号 | XD00185857400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.05 |
| 作者 | 李化奇、张静、魏涛 |
| 绘制单位 | 济南市人民医院、济南市人民医院、济南市人民医院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}