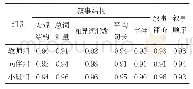
《表3 归类一致性及编码信度系数》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
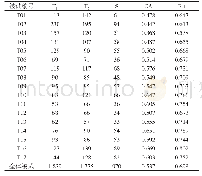
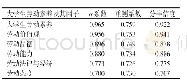
由于质性研究中文本资料编码不一致现象的存在,为确保两名编码者在文本分析、文本理解上保持一致,本文根据如下公式:CA=2×S/(T1+T2),来计算归类一致性指数。其中,S表示两名编码者归类一致数,T1、T2表示每人的编码总数。归类一致性指数值越大,说明两位编码者的编码可信度越高;反之,则越低,最后结果如表3所示。在对隐私声明进行文本分析的过程中,两位编码者具有较高的归类一致性和编码信度。
| 图表编号 | XD00174622000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.01 |
| 作者 | 石婧、潘雅 |
| 绘制单位 | 华中科技大学公共管理学院、华中科技大学公共管理学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}