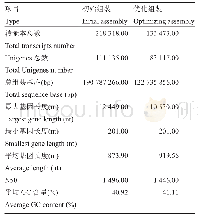
《表1 拼接结果统计:药用资源植物山莨菪的转录组信息分析》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
从头测序组装之后得到158 378个Transcripts,得到71 463个Unigenes,对编码序列进行预测之后得到47 685个CDS(见表1)。对Transcripts而言(图1A),分布在200~300 bp的数量是最多的,其次是300~400 bp(42 231条)、大于等于2 000 bp(19 215条)和300~400 bp(14 864条)。对Unigenes而言(图1B),按分布范围内数量排序的话,依次是200~300 bp(29 326条)、300~400 bp(11 003条)、400~500 bp(5 955条)、大于等于2 000 bp(4 146条);对CDS而言,长度在100~200 nt内的序列最多,有12 928条,占27.11%,其次为200~300 nt(11 259条)、300~400 nt(4 838条)、400~500 nt(2 980条)。无论是Transcripts、Unigenes还是CDS,长度最短的序列数量最多,而随着序列长度增加,所获得的拼接数量就越少(大于等于2 000 bp的序列除外)。Unigenes的平均长度为651.1 bp,最短的Unigene长度为201 bp,最长为8 526 bp,N50长度为1 115 bp,总长度为46 529 443 bp。
| 图表编号 | XD00166429200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.01 |
| 作者 | 张雨、夏铭泽、张发起 |
| 绘制单位 | 中国科学院高原生物适应与进化重点实验室中国科学院西北高原生物研究所、中国科学院大学、中国科学院高原生物适应与进化重点实验室中国科学院西北高原生物研究所、中国科学院大学、中国科学院高原生物适应与进化重点实验室中国科学院西北高原生物研究所 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}