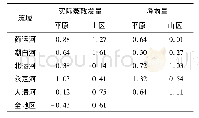
《表3 北京PM2.5序列和子序列排列熵值》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于VMD循环随机跳跃状态网络的时间序列长期预测》
为了进一步表明所提出模型的有效性,选取北京2010年~2014年的气象数据集,对数据集中PM2.5时间序列进行预测.数据中存在缺失值,通过插值法对数据进行修补,此外数据集中存在噪声,需要对其进行去噪处理,减少噪声对预测结果的影响.选取该数据前20 000个数据作为训练数据,后2 000个数据作为测试数据.通过变分模态对北京PM2.5数据进行特征分解,选取模态个数为5.通过排列熵对分解后的特征子序列和原序列进行复杂度估计,得到排列熵值如表3所示,其中IMF0为原始序列的排列熵值.由表3可见,IMF1~IMF4的排列熵值均小于原序列的排列熵值.IMF5的样本熵值比原序列的排列熵值大,由于IMF5的幅值较低,对整个预测结果影响较小.上述分析表明,选取的模态个数合理,变分模态分解能够将复杂特征的时间序列转变成复杂度较低的特征子序列.
| 图表编号 | XD00165483900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.01 |
| 作者 | 韩敏、姜涛、冯守渤 |
| 绘制单位 | 大连理工大学电子信息与电气工程学部、大连理工大学电子信息与电气工程学部、大连理工大学电子信息与电气工程学部 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}