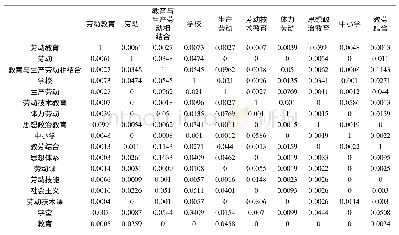
《表3 我国图书馆服务质量研究论文高频关键词相似矩阵 (部分)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为消除频次悬殊造成的影响,采取将词篇矩阵转化为相似矩阵的方法,将共词矩阵中的每个数都除以与之相关的两个关键词总频次开方的乘积[9]。即,利用SPSS19.0导入词篇矩阵,通过分析-相关-距离,度量标准选择相似性和二分类的ochiia,确认后计算距离,得到了32×32相似矩阵(见表3)。矩阵中两个词的对角线上的数据表示某个词与自身的相似程度,相关矩阵中的数字表明的是数据间的相似性,数字的大小表明了相应两个关键词之间的距离远近,数值越大则表明关键词之间的距离越近,相似度越大;反之,相似度越小[10]。由于相似矩阵中0值较多,为减少误差和便于聚类分析,用1减去相关矩阵的每一个数据,从而得到相异矩阵。相异矩阵中的数据,正好与相关矩阵相反,数值越大则表明关键词之间的距离越远,相似度越差;反之,数值越小则表明关键词之间的距离越近,相似度越好[10]。
| 图表编号 | XD0016489100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.11.10 |
| 作者 | 关磊、刘信洪 |
| 绘制单位 | 华南农业大学、华南农业大学 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}