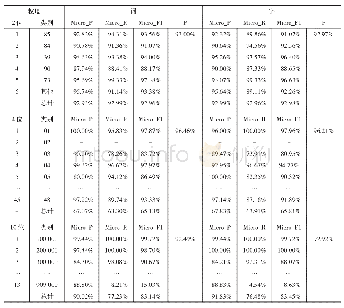
《表5 实验文本敏感程度表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了验证文本敏感信息过滤的可行性,本文抽取2 132篇文本进行编号,然后随机分成4个样本,每个样本含有533篇,将每个样本分给100个人,要求这100个人对文本中的敏感词进行识别统计并对文本的敏感程度进行判断,判断结果分为三类,并分别用不同的符号进行标记,敏感度最高类可表示为A,敏感度中等类可表示为B,无须处理类可表示为C。将100个人判断的每篇文本的敏感词个数取平均值,将100个人判断的文本类别取最多的类别作为最后的分类结果,如表5所示。
| 图表编号 | XD00163334100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.01 |
| 作者 | 余敦辉、张笑笑、付聪、张万山 |
| 绘制单位 | 湖北大学计算机与信息工程学院、湖北省教育信息化工程技术中心、湖北大学计算机与信息工程学院、湖北大学计算机与信息工程学院、湖北大学计算机与信息工程学院、湖北省教育信息化工程技术中心 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}