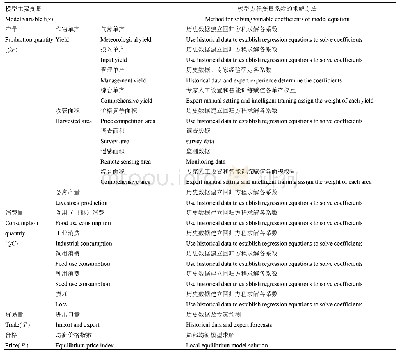
《表1 单机和Hadooop集群求解对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
测试参数的设置如下:“种群”设置为8档(20~4 000)。每个个体都通过Map和Reduce处理,因此,种群的大小等于任务数量。遗传代数设置为1 000,遗传资源的数量也是Map Reduce过程的迭代次数。在实验中,我们通过Hadoop集群和单机实验比较,单机是一个节点求解遗传算法,在Hadoop集群实验中,我们使用2个节点和3个节点并行地求解遗传算法,实验结果的比较如表1所示。
| 图表编号 | XD00148567700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.10 |
| 作者 | 党晓婧、邓世聪、吕启深、许德成、刘伟斌 |
| 绘制单位 | 深圳供电局有限公司、深圳供电局有限公司、深圳供电局有限公司、深圳市康拓普信息技术有限公司、深圳市康拓普信息技术有限公司 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}